A Tensor Processing Unit (TPU) is an Accelerator Application-Specific integrated Circuit (ASIC) developed by Google for Artificial Intelligence and Neural Network Machine Learning. With Machine Learning gaining its relevance and importance every day, the conventional microprocessors have known to be unable to effectively handle the computations be it training or neural network processing.
The 1st Generation TPU is a hardware chip used at Google data center for faster computation. The 2nd generation TPU is now available in cloud and empowers businesses everywhere to access this accelerator technology to speed up their machine learning workloads using its high speed network. The 3rd generation TPU is twice as powerful as its previous generation and this result in an 8-fold increase in performance.
The training and running deep learning models can be computationally demanding, it is where TPU comes into picture. This technology is being used by Google in their various major products like Translate, Photos, Search, Assistant and G-Mail.
TPUs are advantageous in acceleration of computational performance, minimizing the time to accuracy while training complex models, faster development and learning.
1. Introduction
A Tensor Processing Unit (TPU) is an Accelerator Application Specific Integrated Circuit (ASIC) developed by Google for Artificial Intelligence and Neural Network Machine Learning. With Machine Learning gaining its relevance and importance every day, the conventional microprocessors have known to be unable to effectively handle the computations be it training or neural network processing. Graphical Processing Unit(GPU) with their highly parallel architectures designed for graphic processing proved to be way more useful than CPUs for purpose but somewhat lacking. To counter such situations Google developed TPU which would be used by its Tensor Flow Artificial Intelligence framework. Data Scientists, ML Engineers and ML Researchers cannot be maximally productive if they have to wait days or weeks for their model training runs to complete. This technology have significantly reduced the time and enhanced accuracy for common machine learning problems.
2. TensorFlow Framework
TensorFlow is an open source library developed by Google for its internal use. Its main usage is in machine learning and dataflow programming. TensorFlow computations are expressed as stateful dataflow graphs. The name TensorFlow derives from the operations that such neural networks perform on multidimensional data arrays. These arrays are referred to as “tensors”.
3. Types of TPU
3.1 First Generation TPU
The first-generation TPU is an 8-bit matrix multiplication engine, driven with CISC instructions by the host processor across a PCIe 3.0 bus. It is manufactured on a 28 nm process with a die size less than 331 mm2. The clock speed is 700 MHz and it has a thermal design power of 28-40 W. It has 28 MiB of on chip memory, and 4 MiB of 32-bit accumulators taking the results of a 256×256 systolic array of 8-bit multipliers. Within the TPU package is 8 GiB of dual-channel 2133 MHz DDR3 SDRAM offering 34 GB/s of bandwidth. Instructions transfer data to or from the host, perform matrix multiplications or convolutions, and apply activation functions. It was developed to accelerate the machine learning workloads from Google data center.

Figure.1- Google’s first Tensor Processing Unit (TPU) on a printed circuit board (left); TPUs deployed in a Google datacenter (right).
3.2 Second Generation TPU
The second-generation TPU was announced in May 2017. This TPU is now available in cloud and also known as cloud TPU and supports training and inference. Google stated the first-generation TPU design was limited by memory bandwidth and using 16 GB of High Bandwidth Memory in the second-generation design increased bandwidth to 600GB/s and performance to 45 TFLOPS. The TPUs are then arranged into four-chip modules with a performance of 180 TFLOPS. Then 64 of these modules are assembled into 256-chip pods with 11.5 PFLOPS of performance. Notably, while the first-generation TPUs were limited to integers, the second-generation TPUs can also calculate in floating point. This makes the second-generation TPUs useful for both training and inference of machine learning models. Google has stated these second-generation TPUs will be available on the Google Compute Engine for use in TensorFlow applications.

Figure.2- Google’s Cloud Tensor Processing Unit (TPU) and its services.
Cloud TPU chips are interconnected and therefore communication between chips does not have to involve the host CPU or host networking. The APIs used to program Cloud TPU can take advantage of Cloud TPU pods without code changes. As a result, it is easy to scale up to massive compute clusters. The hardware support built into the chips results in effectively linear performance scaling across a broad range of deep learning workloads.
3.3Third Generation TPU
The third-generation TPU was announced on May 8, 2018. Google announced that processors themselves are twice as powerful as the second-generation TPUs, and would be deployed in pods with four times as many chips as the preceding generation. This result in an 8-fold increase in performance per pod compared to the second-generation TPU deployment.

Figure.3-Third Generation TPU.
4. TPU Architecture
4.1 Software Architecture
TPU Estimators are a set of high-level APIs that build upon Estimators which simplify building models for Cloud TPU and which extract maximum TPU performance. When writing a neural network model that uses Cloud TPU, you should use the TPU Estimator APIs.
TPU estimator
TPU Estimators are a set of high-level APIs that build upon Estimators which simplify building models for Cloud TPU and which extract maximum TPU performance. When writing a neural network model that uses Cloud TPU, you should use the TPU Estimator APIs.
TensorFlow client
TPU Estimators translate your programs into TensorFlow operations, which are then converted into a computational graph by a TensorFlow client. A TensorFlow client communicates the computational graph to a TensorFlow server.
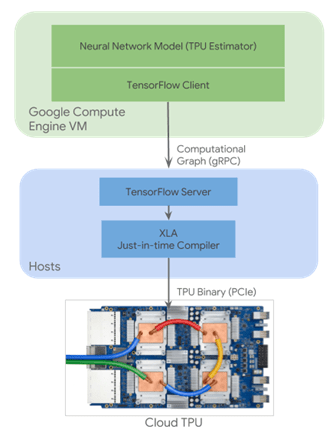
Figure.4-TPU Software Architecture.
TensorFlow server
A TensorFlow server runs on a Cloud TPU server. When the server receives a computational graph from the TensorFlow client, the server performs the following actions:
- loads inputs from Cloud Storage.
- partitions the graph into portions that can run on a Cloud TPU and those that must run on a CPU.
- generates XLA operations corresponding to the sub-graph that is to run on Cloud TPU.
- invokes the XLA compiler.
XLA compiler
XLA is a just-in-time compiler that takes as input High Level Optimizer (HLO) operations that are produced by the TensorFlow server. XLA generates binary code to be run on Cloud TPU, including orchestration of data from on-chip memory to hardware execution units and inter-chip communication. The generated binary is loaded onto Cloud TPU using PCIe connectivity between the Cloud TPU server and the Cloud TPU and is then launched for execution.
4.1 Hardware Architecture
Cloud TPU hardware is comprised of four independent chips. The following block diagram describes the components of a single chip. Each chip consists of two compute cores called Tensor Cores. A Tensor Core consists of scalar, vector and matrix units (MXU). In addition, 8 GB of on-chip memory (HBM) is associated with each Tensor Core for Cloud TPU v2; 16 GB for Cloud TPU v3.
The bulk of the compute horsepower in a Cloud TPU is provided by the MXU. Each MXU is capable of performing 16K multiply-accumulate operations in each cycle. While the MXU’s inputs and outputs are 32-bit floating point values, the MXU performs multiplies at reduced bfloat16 precision. Bfloat16 is a 16-bit floating point representation that provides better training and model accuracy than the IEEE half-precision representation.

Figure.5-TPU Hardware Architecture
The TPU includes the following computational resources:
- Matrix Multiplier Unit (MXU): 65, 536 8-bit multiply-and-add units for matrix operations.
- Unified Buffer (UB): 24MB of SRAM that work as registers
- Activation Unit (AU): Hardwired activation functions.
5. Built for AI on Google Cloud
Architected to run cutting-edge machine learning models with AI services on Google Cloud, Cloud TPU delivers the computational power to transform your business or create the next research breakthrough. With a custom high-speed network that allows TPUs to work together on ML workloads, Cloud TPU can provide up to 11.5 petaflops of performance in a single pod.

Figure.6-AI on Google Cloud
6. TPU in Machine Learning
Machine learning (ML) has enabled breakthroughs across a variety of business and research problems, from strengthening network security to improving the accuracy of medical diagnoses. Because training and running deep learning models can be computationally demanding, we built the Tensor Processing Unit (TPU), an ASIC designed from the ground up for machine learning that powers several of our major products, including Translate, Photos, Search, Assistant, and Gmail. Cloud TPU empowers businesses everywhere to access this accelerator technology to speed up their machine learning workloads on Google Cloud. As shown by the MLPerf benchmark, Google Cloud offers accessible infrastructure for machine learning training at every scale.
Training a machine learning model is analogous to compiling code. Models need to be trained over and over as apps are built, deployed, and refined, so it needs to happen fast and cost-effectively. Cloud TPU provides the performance and cost ideal for ML teams to iterate faster on their solutions.
Example: If you are training an image recognition model and want to train it up to 75% accuracy, a few years ago it would take you days but now it is down to about 12.5 hours in cloud TPU and on full TPU we can do that in less than 12.5 minutes.
7. Real World Applications
TPUs play a huge role in efficient innovation in the field of machine learning. Some of its real world applications are:
- This technology is used to get heart health signals in a completely passive way just by taking the picture of back of the eye. This is a real world application that is going to help to improve people’s lives which is possible with these powerful models (TPU) in machine learning.
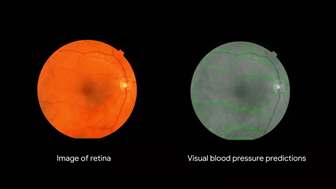
Figure.6-Heart health measurement.
- It used in tracking illegal logging in the rainforests by putting recycled mobile phones in trees which can listen the sounds of chainsaws or other activities and help people protect rainforests in any part of the world.

- It helps in unification of many different application domains. Before different domains like computer vision, speech recognition, machine translation etc. had different implementation techniques from each set. But over the past few years there had been consolidation in deep learning around neural networks that have similar components even if the detail of their structure is different.

Figure.8-Unification of Domains
8. Advantages of TPU
The following are some notable advantages of TPUs:
- Accelerates the performance of linear algebra computation, which is used heavily in machine learning applications.
- Minimizes the time-to-accuracy when you train large, complex neural network models.
- Models that previously took weeks to train on other hardware platforms can converge in hours on TPUs.
9. When to use a TPU?
The following are the cases where TPUs are best suited in machine learning:
- Models dominated by matrix computations.
- Models with no custom TensorFlow operations inside the main training loop.
- Models that train for weeks or months
- Larger and very large models with very large effective batch sizes.
9. Conclusion
This paper presents the design and application of Tensor Processing Unit (TPU) build by Google in the field of machine learning, artificial intelligence and neural networks. Our approach builds on cloud based TPU for interconnection and communication between chips which does not have to involve the host CPU or host networking. As machine learning engineers and researchers tend to work on or train more complex models day to day, it requires more and more efficiency in computation in order to save time and goes to a maximum accuracy. This technology have already showed good results in various Google applications by cutting the training time from certain days to few hours and by interconnected TPU pods it is being done in minutes. Specifically, working with TPU in future would enhance the efficiency to a much higher rate in terms of time and processing making a huge impact on computer industry and lives of millions. A more comprehensive analysis will be possible after more businesses train their models using the cloud TPU service.
